Shard Allocation Explain API
Table of Contents
- 1. Main Idea
- 2. Feedback
- 3. Implementation
[12/12][100%]- 3.1. Reproduction Pieces
- 3.2. Testing explanation with a single node
- 3.3. DONE Add REST endpoint
- 3.4. DONE When decision is "YES" on all nodes, no decisions are returned (even with
include_yes_decisions) - 3.5. DONE Get correct weight from ShardsAllocator (Really
BalancedShardsAllocator) - 3.6. DONE Empty request means "first unassigned shard"
- 3.7. DONE Still show weights even when
include_yes_decisionsis false - 3.8. DONE Unit Tests
- 3.9. DONE Integration Tests
- 3.10. DONE REST Tests
- 3.11. DONE Javadocs for all classes
- 3.12. DONE Asciidoc documentation for feature
- 3.13. DONE Capture exceptions that caused shard failure?
- 3.14. DONE Get weights even when the shard is unassigned
- 4. Multi-node explanation demo and reproduction
- 5. Further work that should be done
- 6. Visualization Ideas
- 7. DONE Hooking into delayed allocation
- 8. CANCELLED Hook into
PrimaryShardsAllocator - 9. CANCELLED Hook into
ReplicaShardsAllocator - 10. DONE Show information when shard is corrupted
- 11. DONE Add output from the indices shard store API
- 12. DONE Hook into the AsyncShardFetch
| Author | Lee Hinman (lee@writequit.org) |
| Date | 2016-08-02 13:57:28 |
1 Main Idea
- Github Issue: https://github.com/elastic/elasticsearch/issues/14593
- Github Pull Request: https://github.com/elastic/elasticsearch/pull/17305
Relates to a comment on #8606 and supersedes #14405.
We currently have the /_cluster/reroute API, that, with the explain and
dry_run parameters allow a user to manually specify an allocation command and
get back an explanation for why that shard can or can not undergo the requested
allocation. This is useful, however, it requires a user to know which node a
shard should be on, and to construct an allocation command for the shard.
I would like to build an API to answer one of the most often asked questions: "Why is my shard UNASSIGNED?"
Instead of it being shard and node specific, I envision an API that looks like:
GET /_cluster/allocation/explain { "index": "myindex" "shard": 0, "primary": false }
Which is basically asking "explain the allocation for a replica of shard 0 for the 'myindex' index".
Here's an idea of how I'd like the response to look:
{
"shard": {
"index": "myindex"
"shard": 0,
"primary": false
},
"cluster_info": {
"nodes": {
"nodeuuid1": {
"lowest_usage": {
"path": "/var/data1",
"free_bytes": 1000,
"used_bytes": 400,
"total_bytes": 1400,
"free_disk_percentage": "71.3%"
"used_disk_percentage": "28.6%"
},
"highest_usage": {
"path": "/var/data2",
"free_bytes": 1200,
"used_bytes": 600,
"total_bytes": 1800,
"free_disk_percentage": "66.6%"
"used_disk_percentage": "33.3%"
}
},
"nodeuuid2": {
"lowest_usage": {
"path": "/var/data1",
"free_bytes": 1000,
"used_bytes": 400,
"total_bytes": 1400,
"free_disk_percentage": "71.3%"
"used_disk_percentage": "28.6%"
},
"highest_usage": {
"path": "/var/data2",
"free_bytes": 1200,
"used_bytes": 600,
"total_bytes": 1800,
"free_disk_percentage": "66.6%"
"used_disk_percentage": "33.3%"
}
},
"nodeuuid3": {
"lowest_usage": {
"path": "/var/data1",
"free_bytes": 1000,
"used_bytes": 400,
"total_bytes": 1400,
"free_disk_percentage": "71.3%"
"used_disk_percentage": "28.6%"
},
"highest_usage": {
"path": "/var/data2",
"free_bytes": 1200,
"used_bytes": 600,
"total_bytes": 1800,
"free_disk_percentage": "66.6%"
"used_disk_percentage": "33.3%"
}
}
},
"shard_sizes": {
"[myindex][0][P]": 1228718,
"[myindex][0][R]": 1231289,
"[myindex][1][P]": 1248718,
"[myindex][1][R]": 1298718,
}
},
"nodes": {
"nodeuuid1": {
"final_decision": "NO"
"decisions": [
{
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "shard cannot be allocated on same node [JZU4UIPFQtWn34FyAH6VoQ] it already exists on"
},
{
"decider" : "snapshot_in_progress",
"decision" : "NO",
"explanation" : "a snapshot is in progress"
}
],
"weight": 1.9
}
"nodeuuid2": {
"final_decision": "NO"
"decisions": [
{
"decider" : "node_version",
"decision" : "NO",
"explanation" : "target node version [1.4.0] is older than source node version [1.7.3]"
}
],
"weight": 1.3
}
"nodeuuid3": {
"final_decision": "YES"
"decisions": [],
"weight": 0.9
}
}
}
1.1 Parts of the response
Breaking down the parts:
1.1.1 shard
The same information passed into the request, so it is contained in the request itself as well.
1.1.2 cluster_info
This roughly relates to https://github.com/elastic/elasticsearch/issues/14405, however, I realized this API is not node-specific, so putting it in nodes' stats API doesn't make sense. Instead, it's master-only information used for allocation. Since this is gathered and used for allocation, it makes sense to expose it here since it influences the final decision.
1.1.3 nodes
This is a map where each key is the node uuid (should probably include the node name as well to be helpful). It has sub keys:
1.1.3.1 final_decision
A simple "YES" or "NO" for whether the shard can currently be allocated on this node.
1.1.3.2 decisions
A list of all the "NO" decisions preventing allocation on this node. I could see a flag being added to include all the "YES" decisions, but I think it should default to showing "NO" only to prevent it being too verbose.
1.1.3.3 weight
I'd like to change the ShardAllocator interface to add the ability to "weigh"
a shard for a node, with whatever criteria it usually balances with. For
example, with the BalancedShardsAllocator, the weight would be the calculation
based on the number of shards for the index as well as the shard count.
I could see this being useful for answering the question "Okay, if all the decisions where 'YES', where would this shard likely end up?".
It might be trickier to implement, but it could be added on at a later time.
2 Feedback
This is various feedback I got on the issue. Some of which I incorporated and some that I have not yet incorporated.
From Glen:
Skip the step of finding the unallocated shards and asking about each of them individually, and just
GET /_cluster/allocation/explain { "index": "myindex", "shard": { "state": "unallocated" } }
From Clint:
I like the idea a lot, but I'd reorganise things a bit, especially so it works better in the 500 node case. I think the disk usage stats should also be available in the nodes stats API. In this API, I'd perhaps include the disk (relevant?) usage stats in the disk usage decider, rather than in a separate section (ie put it where it is relevant).
Perhaps default to a non-verbose output which doesn't list every YES decision, but only the first NO decision for each node.
3 Implementation [12/12] [100%]
3.1 Reproduction Pieces
These are the individual pieces of manually testing the allocation explain API
Resetting the cluster:
DELETE /_all {} PUT /myindex { "settings": { "index.number_of_shards": 3, "index.number_of_replicas": 1 } } GET /_cluster/health?wait_for_status=yellow {}
Turning on additional logging:
PUT /_cluster/settings { "transient": { "logger._root": "INFO", "logger.action.admin.cluster.allocation": "DEBUG" } }
Try to explain things:
GET /_cluster/allocation/explain?pretty { "index": "myindex", "shard": 0, "primary": false }
Explaining things with the include_yes_decisions option:
GET /_cluster/allocation/explain?pretty&include_yes_decisions=true { "index": "myindex", "shard": 0, "primary": false }
3.2 Testing explanation with a single node
This is the basic repro We should parse something like this:
DELETE /_all {} PUT /myindex { "settings": { "index.number_of_shards": 3, "index.number_of_replicas": 1 } } GET /_cluster/health?wait_for_status=yellow {} PUT /_cluster/settings { "transient": { "logger._root": "INFO", "logger.action.admin.cluster.allocation": "DEBUG" } } GET /_cluster/allocation/explain?pretty { "index": "myindex", "shard": 0, "primary": false } GET /_cluster/allocation/explain?pretty&include_yes_decisions=true { "index": "myindex", "shard": 0, "primary": false }
{"acknowledged":true}
{"acknowledged":true}
{"cluster_name":"distribution_run","status":"yellow","timed_out":false,"number_of_nodes":1,"number_of_data_nodes":1,"active_primary_shards":3,"active_shards":3,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":3,"delayed_unassigned_shards":0,"number_of_pending_tasks":3,"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":19,"active_shards_percent_as_number":50.0}
{
"shard" : {
"index" : "myindex",
"index_uuid" : "gzvq2fp0SjSZZdv8rSrrEg",
"id" : 0,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-03-30T21:00:48.789Z"
},
"nodes" : {
"dQoadMLySMy-EVBaNAg4mg" : {
"node_name" : "Stellaris",
"node_attributes" : {
"testattr" : "test"
},
"final_decision" : "NO",
"weight" : 3.0,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [dQoadMLySMy-EVBaNAg4mg] on which it already exists"
} ]
}
}
}
{
"shard" : {
"index" : "myindex",
"index_uuid" : "gzvq2fp0SjSZZdv8rSrrEg",
"id" : 0,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-03-30T21:00:48.789Z"
},
"nodes" : {
"dQoadMLySMy-EVBaNAg4mg" : {
"node_name" : "Stellaris",
"node_attributes" : {
"testattr" : "test"
},
"final_decision" : "NO",
"weight" : 3.0,
"decisions" : [ {
"decider" : "enable",
"decision" : "YES",
"explanation" : "all allocations are allowed"
}, {
"decider" : "snapshot_in_progress",
"decision" : "YES",
"explanation" : "the shard is not primary or relocation is disabled"
}, {
"decider" : "disk_threshold",
"decision" : "YES",
"explanation" : "there is only a single data node present"
}, {
"decider" : "shards_limit",
"decision" : "YES",
"explanation" : "total shard limits are disabled: [index: -1, cluster: -1] <= 0"
}, {
"decider" : "node_version",
"decision" : "YES",
"explanation" : "target node version [5.0.0-alpha1] is the same or newer than source node version [5.0.0-alpha1]"
}, {
"decider" : "replica_after_primary_active",
"decision" : "YES",
"explanation" : "primary shard for this replica is already active"
}, {
"decider" : "awareness",
"decision" : "YES",
"explanation" : "allocation awareness is not enabled"
}, {
"decider" : "throttling",
"decision" : "YES",
"explanation" : "below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2]"
}, {
"decider" : "filter",
"decision" : "YES",
"explanation" : "node passes include/exclude/require filters"
}, {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [dQoadMLySMy-EVBaNAg4mg] on which it already exists"
} ]
}
}
}
3.4 DONE When decision is "YES" on all nodes, no decisions are returned (even with include_yes_decisions)
This was because I short-circuited the code path. This should be fixed now.
Weird thing with this is that even if the shard is already assigned, it "can't" be assigned because it can't be assigned to the node it's already on. Need to decide whether to fix this by ignoring the node it's already on, or whether it's okay to punt on it.
GET /_cluster/allocation/explain?pretty&include_yes_decisions=true { "index": "myindex", "shard": 0, "primary": true }
{
"shard" : {
"index" : "myindex",
"index_uuid" : "lUsrCLV3S-6cmZtaZrIFzQ",
"id" : 0,
"primary" : true
},
"assigned" : true,
"assigned_node_id" : "AwXAnjtYQXGFUbqebnBKjg",
"nodes" : {
"AwXAnjtYQXGFUbqebnBKjg" : {
"node_name" : "Mogul of the Mystic Mountain",
"node_attributes" : {
"portsfile" : "true",
"testattr" : "test"
},
"final_decision" : "CURRENTLY_ASSIGNED",
"weight" : 0.0,
"decisions" : [ {
"decider" : "shards_limit",
"decision" : "YES",
"explanation" : "total shard limits are disabled: [index: -1, cluster: -1] <= 0"
}, {
"decider" : "replica_after_primary_active",
"decision" : "YES",
"explanation" : "shard is primary and can be allocated"
}, {
"decider" : "node_version",
"decision" : "YES",
"explanation" : "target node version [5.0.0] is the same or newer than source node version [5.0.0]"
}, {
"decider" : "filter",
"decision" : "YES",
"explanation" : "node passes include/exclude/require filters"
}, {
"decider" : "disk_threshold",
"decision" : "YES",
"explanation" : "there is only a single data node present"
}, {
"decider" : "enable",
"decision" : "YES",
"explanation" : "all allocations are allowed"
}, {
"decider" : "snapshot_in_progress",
"decision" : "YES",
"explanation" : "no snapshots are currently running"
}, {
"decider" : "throttling",
"decision" : "YES",
"explanation" : "below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2]"
}, {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [AwXAnjtYQXGFUbqebnBKjg] on which it already exists"
}, {
"decider" : "awareness",
"decision" : "YES",
"explanation" : "allocation awareness is not enabled"
} ]
}
}
}
3.5 DONE Get correct weight from ShardsAllocator (Really BalancedShardsAllocator)
I semi-implemented this, but it isn't working correctly right now.
This is working now, the implementation is a bit different. The higher the score the more the shard would like to move to that node.
3.6 DONE Empty request means "first unassigned shard"
Instead of having to look at which shards are unassigned, an empty request should pick the first unassigned shard and explain it.
Request with an empty JSON object:
GET /_cluster/allocation/explain?pretty {}
{
"shard" : {
"index" : "myindex",
"index_uuid" : "gzvq2fp0SjSZZdv8rSrrEg",
"id" : 1,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-03-30T21:00:48.789Z"
},
"nodes" : {
"dQoadMLySMy-EVBaNAg4mg" : {
"node_name" : "Stellaris",
"node_attributes" : {
"testattr" : "test"
},
"final_decision" : "NO",
"weight" : 3.0,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [dQoadMLySMy-EVBaNAg4mg] on which it already exists"
} ]
}
}
}
Curl request with no body:
curl -XGET 'localhost:9200/_cluster/allocation/explain?pretty'
{
"shard" : {
"index" : "myindex",
"index_uuid" : "gzvq2fp0SjSZZdv8rSrrEg",
"id" : 1,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-03-30T21:00:48.789Z"
},
"nodes" : {
"dQoadMLySMy-EVBaNAg4mg" : {
"node_name" : "Stellaris",
"node_attributes" : {
"testattr" : "test"
},
"final_decision" : "NO",
"weight" : 3.0,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [dQoadMLySMy-EVBaNAg4mg] on which it already exists"
} ]
}
}
}
3.7 DONE Still show weights even when include_yes_decisions is false
This currently doesn't list any nodes at all if the shard is already assigned, it'd be nice to show the weights even if the decisions are all "YES"
GET /_cluster/allocation/explain?pretty { "index": "myindex", "shard": 0, "primary": true }
{
"shard" : {
"index" : "myindex",
"index_uuid" : "fhB4kM_jQo-OKst0aO8n9g",
"id" : 0,
"primary" : true
},
"assigned" : true,
"assigned_node_id" : "q562OSHRQwKxORaPBZizzw",
"nodes" : {
"q562OSHRQwKxORaPBZizzw" : {
"node_name" : "Barnacle",
"node_attributes" : {
"testattr" : "test",
"portsfile" : "true"
},
"final_decision" : "CURRENTLY_ASSIGNED",
"weight" : 0.0,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [q562OSHRQwKxORaPBZizzw] on which it already exists"
} ]
}
}
}
3.13 DONE Capture exceptions that caused shard failure?
In the event the data is corrupt or something, it'd be great if we didn't have to look at the logs to see what was going wrong, but could see it from this API (the stacktrace)
I think UnassignedInfo may already support this, I just need to check and test
it manually to see.
I checked this, UnassignedInfo will serialize this if it exists, so this
should be covered.
4 Multi-node explanation demo and reproduction
Here I set up three nodes:
GET /_cat/nodes?v {}
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 127.0.0.1 3 93 26 1.66 2.53 1.94 mdi - Trick Shot 127.0.0.1 3 93 29 1.66 2.53 1.94 mdi - Horus 127.0.0.1 4 93 31 1.66 2.53 1.94 mdi * Orikal
One of them has the node.foo=bar attribute, and two have node.bar=baz
attributes.
Create an index that can go on all three nodes, an index that can only go on the
baz nodes, and finally an index that can only go on the "foo" node:
DELETE /anywhere,only-baz,only-foo {} POST /anywhere {} POST /only-baz { "index.routing.allocation.include.bar": "baz" } POST /only-foo { "index.routing.allocation.include.foo": "bar", "index.number_of_shards": 1, "index.number_of_replicas": 1 }
{"acknowledged":true}
{"acknowledged":true}
{"acknowledged":true}
{"acknowledged":true}
This leads us with this allocation:
GET /_cat/shards?v {} GET /_cat/allocation?v {}
index shard prirep state docs store ip node only-baz 3 r STARTED 0 130b 127.0.0.1 Trick Shot only-baz 3 p STARTED 0 130b 127.0.0.1 Horus only-baz 4 p STARTED 0 0b 127.0.0.1 Trick Shot only-baz 4 r STARTED 0 130b 127.0.0.1 Horus only-baz 1 r STARTED 0 130b 127.0.0.1 Trick Shot only-baz 1 p STARTED 0 0b 127.0.0.1 Horus only-baz 2 p STARTED 0 0b 127.0.0.1 Trick Shot only-baz 2 r STARTED 0 130b 127.0.0.1 Horus only-baz 0 p STARTED 0 130b 127.0.0.1 Trick Shot only-baz 0 r STARTED 0 130b 127.0.0.1 Horus anywhere 3 p STARTED 0 0b 127.0.0.1 Orikal anywhere 3 r STARTED 0 130b 127.0.0.1 Trick Shot anywhere 1 p STARTED 0 0b 127.0.0.1 Trick Shot anywhere 1 r STARTED 0 0b 127.0.0.1 Horus anywhere 4 p STARTED 0 130b 127.0.0.1 Trick Shot anywhere 4 r STARTED 0 130b 127.0.0.1 Horus anywhere 2 r STARTED 0 0b 127.0.0.1 Trick Shot anywhere 2 p STARTED 0 130b 127.0.0.1 Horus anywhere 0 p STARTED 0 130b 127.0.0.1 Orikal anywhere 0 r STARTED 0 130b 127.0.0.1 Horus only-foo 0 p STARTED 0 130b 127.0.0.1 Trick Shot only-foo 0 r UNASSIGNED shards disk.indices disk.used disk.avail disk.total disk.percent host ip node 10 780b 179.2gb 216.8gb 396.1gb 45 127.0.0.1 127.0.0.1 Trick Shot 9 910b 179.2gb 216.8gb 396.1gb 45 127.0.0.1 127.0.0.1 Horus 2 130b 179.2gb 216.8gb 396.1gb 45 127.0.0.1 127.0.0.1 Orikal 1 UNASSIGNED
Now, let's explain the allocation of the only-foo index 0-th replica shard!
GET /_cluster/allocation/explain?pretty { "index": "only-foo", "shard": 0, "primary": false }
{
"shard" : {
"index" : "only-foo",
"index_uuid" : "tGIs2IXMT2Wk0B-rRkyJNA",
"id" : 0,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-04-12T17:47:07.657Z"
},
"allocation_delay" : "0s",
"allocation_delay_ms" : 0,
"remaining_delay" : "0s",
"remaining_delay_ms" : 0,
"nodes" : {
"3d9C_UuPQGWenjnZDeuTeA" : {
"node_name" : "Trick Shot",
"node_attributes" : {
"bar" : "baz",
"foo" : "bar"
},
"final_decision" : "NO",
"weight" : -1.3833332,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [3d9C_UuPQGWenjnZDeuTeA] on which it already exists"
} ],
"store" : {
"allocation_id" : "fXD2SF3gRxu3qxWVAXvygA",
"allocation" : "PRIMARY"
}
},
"_QHThUFmTUOXX_NOGh4rZg" : {
"node_name" : "Horus",
"node_attributes" : {
"bar" : "baz"
},
"final_decision" : "NO",
"weight" : -0.3833332,
"decisions" : [ {
"decider" : "filter",
"decision" : "NO",
"explanation" : "node does not match index include filters [foo:\"bar\"]"
} ],
"store" : { }
},
"qM5Jpo25SjCELqEmrGYawg" : {
"node_name" : "Orikal",
"node_attributes" : { },
"final_decision" : "NO",
"weight" : 2.766667,
"decisions" : [ {
"decider" : "filter",
"decision" : "NO",
"explanation" : "node does not match index include filters [foo:\"bar\"]"
} ],
"store" : { }
}
}
}
Notice that the shard cannot be allocated anywhere, and that it would like to put it on the node with a weight of 2.316.
Now, if we explain the primary version of the shard, we can see:
GET /_cluster/allocation/explain?pretty { "index": "only-foo", "shard": 0, "primary": true }
{
"shard" : {
"index" : "only-foo",
"index_uuid" : "6pTEF0BgT0uh5oLLSuIlXQ",
"id" : 0,
"primary" : true
},
"assigned" : true,
"assigned_node_id" : "HcIafh5kQLSi9aM8JVeQew",
"nodes" : {
"7ga-DXgTSwSRJFLuVvXnCA" : {
"node_name" : "Sinister",
"node_attributes" : {
"bar" : "baz"
},
"final_decision" : "NO",
"weight" : 1.0,
"decisions" : [ {
"decider" : "filter",
"decision" : "NO",
"explanation" : "node does not match index include filters [foo:\"bar\"]"
} ]
},
"HcIafh5kQLSi9aM8JVeQew" : {
"node_name" : "Mad Dog Rassitano",
"node_attributes" : {
"bar" : "baz",
"foo" : "bar"
},
"final_decision" : "CURRENTLY_ASSIGNED",
"weight" : 0.0,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [HcIafh5kQLSi9aM8JVeQew] on which it already exists"
} ]
},
"IKqmnqtOQQeKqc4MyBv7QA" : {
"node_name" : "Bullet",
"node_attributes" : { },
"final_decision" : "NO",
"weight" : 2.8,
"decisions" : [ {
"decider" : "filter",
"decision" : "NO",
"explanation" : "node does not match index include filters [foo:\"bar\"]"
} ]
}
}
}
POST /_cluster/allocation/explain?pretty {}
{
"shard" : {
"index" : "only-foo",
"index_uuid" : "6pTEF0BgT0uh5oLLSuIlXQ",
"id" : 0,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-03-31T15:56:52.628Z"
},
"nodes" : {
"7ga-DXgTSwSRJFLuVvXnCA" : {
"node_name" : "Sinister",
"node_attributes" : {
"bar" : "baz"
},
"final_decision" : "NO",
"weight" : 0.06666675,
"decisions" : [ {
"decider" : "filter",
"decision" : "NO",
"explanation" : "node does not match index include filters [foo:\"bar\"]"
} ]
},
"HcIafh5kQLSi9aM8JVeQew" : {
"node_name" : "Mad Dog Rassitano",
"node_attributes" : {
"bar" : "baz",
"foo" : "bar"
},
"final_decision" : "NO",
"weight" : -0.9333332,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [HcIafh5kQLSi9aM8JVeQew] on which it already exists"
} ]
},
"IKqmnqtOQQeKqc4MyBv7QA" : {
"node_name" : "Bullet",
"node_attributes" : { },
"final_decision" : "NO",
"weight" : 1.8666667,
"decisions" : [ {
"decider" : "filter",
"decision" : "NO",
"explanation" : "node does not match index include filters [foo:\"bar\"]"
} ]
}
}
}
It's currently assigned on one node (the one with CURRENTLY_ASSIGNED and a
weight of 0.0), but it would like to go to other two nodes, with the higher
weights (the higher the weight, the more the balancer would like to put the
shard on that node).
5 Further work that should be done
This is a good start, but there's further work that can be done. Yannick brought up some good comments on the PR and led to opening a subsequent issue #17372 where we also expose information about allocation when a shard is unassigned due to:
[ ]primary shard unassigned as only stale shard copies available (allocation ids don't match)[X]replica shard unassigned due to delayed shard allocation (node_left.delayed_timeout)[ ]primary or replica shard unassigned as shard fetching is still going on (i.e. not all data available yet to decide where to place the shard)
6 Visualization Ideas
Some future ideas about how this could be visualized in Marvel or something. To start with, we would have a dashboard that displayed the nodes as boxes with shards inside of them. Think similar to the way the training currently diagrams shards on a node. We would have to figure out a good way to limit the number of shards shown so it doesn't overwhelm a user.
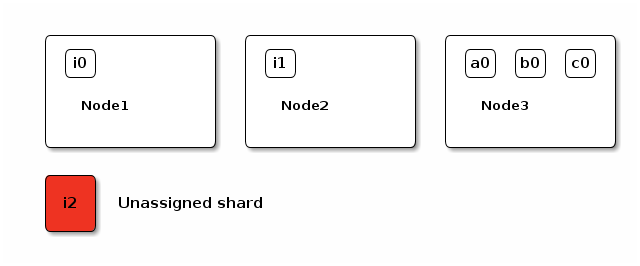
Figure 1: Three nodes with a single unassigned shard
The i2 shard is unassigned, a user should be able to click on it and get an
explanation for why that particular shard isn't allocated to a node. In the
background, Marvel would send a request like:
POST /_cluster/allocation/explain { "index": "i", "shard": 2, "primary": true }
When the results come back from the user clicking on the i2 shard, Marvel can
show a breakdown of the results with something like:
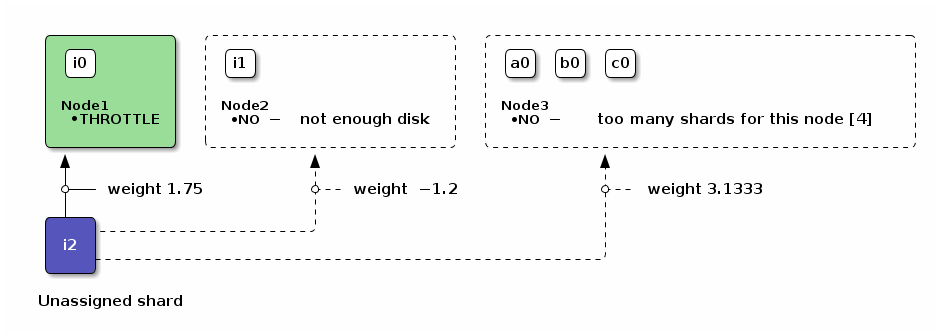
Figure 2: Explaining the allocation the "i2" shard when a user clicks on it
| Color | Meaning |
|---|---|
| Red | Unable to be allocated |
| Green | Shard can be allocated |
| Blue | Shard is being throttled |
| Dotted | Node has a final decision of "NO" |
This would give an overview of where ES would like to place the shard, why it can't be allocated to the node, and whether it can be allocated at all.
7 DONE Hooking into delayed allocation
Found out this is actually exposed in UnassignedInfo, so it should be simple
just to add it to the response.
Github pull request for this: https://github.com/elastic/elasticsearch/pull/17515
7.1 Showing delayed allocation
Start with three nodes
GET /_cat/nodes?v {}
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 127.0.0.1 6 89 44 2.41 1.51 0.95 mdi * Caretaker 127.0.0.1 4 89 28 2.41 1.51 0.95 mdi - Blind Justice 127.0.0.1 5 89 39 2.41 1.51 0.95 mdi - Landslide
Create an index with normal settings
DELETE /i {} POST /i {}
{"acknowledged":true}
{"acknowledged":true}
Shards are all good:
GET /_cat/shards?v {}
index shard prirep state docs store ip node i 2 r STARTED 0 130b 127.0.0.1 Caretaker i 2 p STARTED 0 130b 127.0.0.1 Landslide i 1 p STARTED 0 130b 127.0.0.1 Blind Justice i 1 r STARTED 0 130b 127.0.0.1 Landslide i 4 p STARTED 0 130b 127.0.0.1 Blind Justice i 4 r STARTED 0 130b 127.0.0.1 Landslide i 3 p STARTED 0 130b 127.0.0.1 Caretaker i 3 r STARTED 0 130b 127.0.0.1 Blind Justice i 0 p STARTED 0 130b 127.0.0.1 Caretaker i 0 r STARTED 0 130b 127.0.0.1 Landslide
Now we'll kill a node and then immediately explain the replica, it should show the allocation delay in millis and human-readable time. In this case, I shut down "Blind Justice"
GET /_cluster/allocation/explain?pretty { "index": "i", "shard": 3, "primary": false }
{
"shard" : {
"index" : "i",
"index_uuid" : "QzoKda9aQCG_hCaZQ18GEg",
"id" : 3,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "NODE_LEFT",
"at" : "2016-04-04T16:44:47.520Z",
"details" : "node_left[HyRLmMLxR5m_f58RKURApQ]"
},
"allocation_delay" : "59.9s",
"allocation_delay_ms" : 59910,
"remaining_delay" : "38.9s",
"remaining_delay_ms" : 38991,
"nodes" : {
"jKiyQcWFTkyp3htyyjxoCw" : {
"node_name" : "Landslide",
"node_attributes" : { },
"final_decision" : "YES",
"weight" : 1.0,
"decisions" : [ ]
},
"9bzF0SgoQh-G0F0sRW_qew" : {
"node_name" : "Caretaker",
"node_attributes" : { },
"final_decision" : "NO",
"weight" : 2.0,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [9bzF0SgoQh-G0F0sRW_qew] on which it already exists"
} ]
}
}
}
Decision is YES, but can't be allocated due to a delay. This section has been added:
... "allocation_delay" : "59.9s", "allocation_delay_ms" : 59910, "remaining_delay" : "38.9s", "remaining_delay_ms" : 38991, ...
10 DONE Show information when shard is corrupted
I thought this was already implemented, but it looks like UnassignedInfo
doesn't already show this in its toXContent method.
I used this utility: https://github.com/joshsegall/corrupt to corrupt some segment files for a node.
GET /_cat/shards?v {}
index shard prirep state docs store ip node i 4 p STARTED 0 130b 127.0.0.1 Captain Zero i 4 r UNASSIGNED i 3 p STARTED 0 130b 127.0.0.1 Captain Zero i 3 r UNASSIGNED i 2 p STARTED 0 130b 127.0.0.1 Captain Zero i 2 r UNASSIGNED i 1 p UNASSIGNED i 1 r UNASSIGNED i 0 p UNASSIGNED i 0 r UNASSIGNED
POST /_cluster/allocation/explain?pretty { "index": "i", "shard": 1, "primary": true }
{
"shard" : {
"index" : "i",
"index_uuid" : "QzoKda9aQCG_hCaZQ18GEg",
"id" : 1,
"primary" : true
},
"assigned" : false,
"unassigned_info" : {
"reason" : "ALLOCATION_FAILED",
"at" : "2016-04-08T20:11:35.917Z",
"details" : "failed recovery, failure IndexShardRecoveryException[failed to fetch index version after copying it over]; nested: IndexShardRecoveryException[shard allocated for local recovery (post api), should exist, but doesn't, current files: [segments_3, write.lock]]; nested: IndexFormatTooOldException[Format version is not supported (resource BufferedChecksumIndexInput(NIOFSIndexInput(path=\"/home/hinmanm/scratch/elasticsearch-5.0.0-alpha1-SNAPSHOT/data/elasticsearch/nodes/0/indices/QzoKda9aQCG_hCaZQ18GEg/1/index/segments_3\"))): 317397653 (needs to be between 1071082519 and 1071082519). This version of Lucene only supports indexes created with release 5.0 and later.]; "
},
"allocation_delay" : "0s",
"allocation_delay_ms" : 0,
"remaining_delay" : "0s",
"remaining_delay_ms" : 0,
"nodes" : {
"pGr91SvnS_yhC2fBA-95Yw" : {
"node_name" : "Captain Zero",
"node_attributes" : { },
"final_decision" : "YES",
"weight" : 7.0,
"decisions" : [ ]
}
}
}
So it looks like this works, however, there's a small issue for this where shards are not even tried if a corruption has already occurred with a shard. I opened an issue for this here: https://github.com/elastic/elasticsearch/issues/17630
It turns out this might be a race condition between the async fetch API and the shard state one, Boaz is going to open an issue.
11 DONE Add output from the indices shard store API
It would be great if we could encapsulate the shard store information also, it would help when explaining where a shard could go to
POST /i {}
{"acknowledged":true}
This is the happy case when a shard is not corrupt. There's no exception and you just get information about the shard store.
GET /_cluster/allocation/explain?pretty { "index": "i", "shard": 0, "primary": false }
{
"shard" : {
"index" : "i",
"index_uuid" : "de1W1374T4qgvUP4a9Ieaw",
"id" : 0,
"primary" : false
},
"assigned" : false,
"unassigned_info" : {
"reason" : "INDEX_CREATED",
"at" : "2016-04-26T16:34:53.227Z"
},
"allocation_delay_ms" : 0,
"remaining_delay_ms" : 0,
"nodes" : {
"z-CbkiELT-SoWT91HIszLA" : {
"node_name" : "Brain Cell",
"node_attributes" : {
"testattr" : "test"
},
"store" : {
"shard_copy" : "AVAILABLE"
},
"final_decision" : "NO",
"final_explanation" : "the shard cannot be assigned because one or more allocation decider returns a 'NO' decision",
"weight" : 5.0,
"decisions" : [ {
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated on the same node id [z-CbkiELT-SoWT91HIszLA] on which it already exists"
} ]
}
}
}
11.1 Explaining a corrupted shard
Using the reproduction from the previous headline (when a shard is corrupted):
POST /_cluster/allocation/explain?pretty { "index": "i", "shard": 0, "primary": true }
{
"shard" : {
"index" : "i",
"index_uuid" : "WxAuxGpdSX6ezspqgtsMyQ",
"id" : 0,
"primary" : true
},
"assigned" : false,
"unassigned_info" : {
"reason" : "CLUSTER_RECOVERED",
"at" : "2016-04-25T18:32:13.871Z"
},
"allocation_delay" : "0s",
"allocation_delay_ms" : 0,
"remaining_delay" : "0s",
"remaining_delay_ms" : 0,
"nodes" : {
"2Abe7B9ATvKKnKfRyGucFg" : {
"node_name" : "Jester",
"node_attributes" : { },
"store" : {
"shard_copy" : "IO_ERROR",
"store_exception" : "CorruptIndexException[misplaced codec footer (file extended?): remaining=32, expected=16, fp=179 (resource=BufferedChecksumIndexInput(SimpleFSIndexInput(path=\"/home/hinmanm/scratch/elasticsearch-5.0.0-SNAPSHOT/data/elasticsearch/nodes/0/indices/WxAuxGpdSX6ezspqgtsMyQ/0/index/segments_2\")))]"
},
"final_decision" : "NO",
"final_explanation" : "there was an IO error reading from data in the shard store",
"weight" : 6.0,
"decisions" : [ ]
}
}
}
Hooray! It work great! There is a new store map that includes all the
store-related problems with a shard.
Opened a PR for this: https://github.com/elastic/elasticsearch/pull/17689
12 DONE Hook into the AsyncShardFetch
We should show whether a shard is currently being fetched or not
Added this here: https://github.com/elastic/elasticsearch/pull/18119