Stress run with queue auto-adjustment
Table of Contents
| Author | Lee Hinman (lee@elastic.co) |
| Date | 2017-05-02 12:02:23 |
1 Explanation
Run on 120 million documents, with a function_score query with decay as well as a large terms
query.
Okay, I ran some benchmarks with this change, there are a number of things I found that were interesting. Some that caused me to rethink the design, keep reading below for the update.
I tested this on a 6-node cluster with 5 extremely beefy data nodes (32 CPUs, 64gb RAM, JVM heap at 30gb) and a single client node (to which all the requests were sent). The cluster was loaded with 120 million documents on an index with 5 primaries and 4 replicas (so each node could serve a request for any shard).
I used Pius' setup for JMeter to spawn 5 threads each running 40000 queries at a target rate of 20 queries a second (so with 5 threads it'd be targeted at 100 queries a second).
The query was a fairly complex query with function_score with multiple decay functions, expression
scripts, geo_distance, and an extremely large terms filter.
During this test, I consistently stressed a single node by using
stress -i 8 -c 8 -m 8 -d 8
This does the following:
- spawn 8 workers spinning on
sqrt() - spawn 8 workers spinning on
sync() - spawn 8 workers spinning on
malloc()/free() - spawn 8 workers spinning on
write()/unlink()
I did this to simulate a situation where one node in a cluster cannot keep up, whether because of an expensive query, or degraded disk, etc.
1.1 The desired behavior
The behavior I'd like to see in this situation is that the stressed node (es5) would eventually lower its threadpool queue down to a level where it would start rejecting requests, causing other nodes in the cluster to serve them. This would lead to better overall performance since the load would be routed away from the overloaded node.
1.2 The results with this branch as-is
First I tried this branch as-is, I measured how the threadpools changed and whether the desired behavior was accomplished.
Spoiler alert: It was not.
My initial premise was based on the (deceptively simple) Little's Law formula of
L = λW
Where L is the optimal queue size, λ is the arrival rate of events, and W is the average time
it takes to process a request.
I was measuring both λ and W, and calculating L to be used for the queue size.
I discovered a number of issues with this premise. First, by leaving both λ and W as
"calculated" metrics, L is reported rather than targeted. This means that on es5, as W (avg
response time) got higher due to the node being loaded, the estimated queue actually increased,
which was not desired. I went back to the drawing board.
1.3 The alternative implementation
"Okay" I thought, I need to make the relationship between the optimal queue size and actual queue
size inverse, so that as the "optimal" queue went up, the actual queue size went down. The second
thing I tried was to take the maximum queue size and subtract the optimal queue size, so that as the
optimal queue size went up (L, also known as the long-term average number of tasks in the queue),
the actual queue would go down.
This sort of worked, but it had a number of issues -
It felt hacky, and not like an actual good implementation, being able to set a good maximum queue size would be almost impossible without knowing up front what your queue size already was at, set too high of a max and the adjustment would have no effect, too low and you'd be rejecting before you actually had stress on the node.
Additionally, it suffered the same problem as the previous solution, both λ and W were being
measured, when they really should not be, which leads me to..
1.4 The alternative-alternative implementation
Back to the drawing board, I spent some time thinking and realized that we should not be measuring
both λ and W, and determining L, rather, one variable should be configured, one measured, and
one the resulting optimal value.
With this in mind, I implemented an alternative where W was set by the user as a
target_response_rate, this is a level where the user would essentially configure a value saying
"I am targeting my requests to all take less than N on average for a healthy node".
I then use λ to be the measured task rate, similar to how I did before, this means that with a
target_response_rate of 5 seconds and task rate of 15 queries/second, there should be at most
15 * 5 = 75 events in the queue at peak usage.
I tested my theory; with the same setup, I set up a target_response_rate of 5 seconds and
adjustment amount of 50 (the queue would go up or down by 50 each time, just makes it easier to read
the logs). I knew that this was a particularly complex query that I would be throwing at the nodes,
and 5 seconds was a reasonable average response time.
I am happy to report that with my initial testing, I was able to show that with this setup, the stressed node correctly routed traffic away from itself by lowering and subsequently rejecting search requests, routing them to the unstressed nodes, and improving average response times for the entire run.
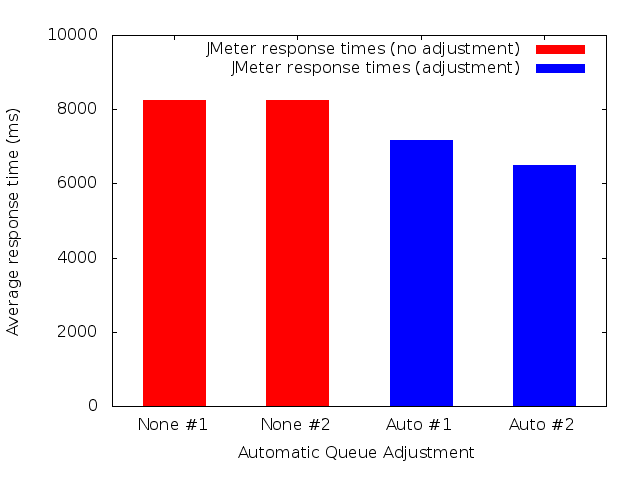
Below are graphs of the response times with "None" and "Auto" queue adjustment:
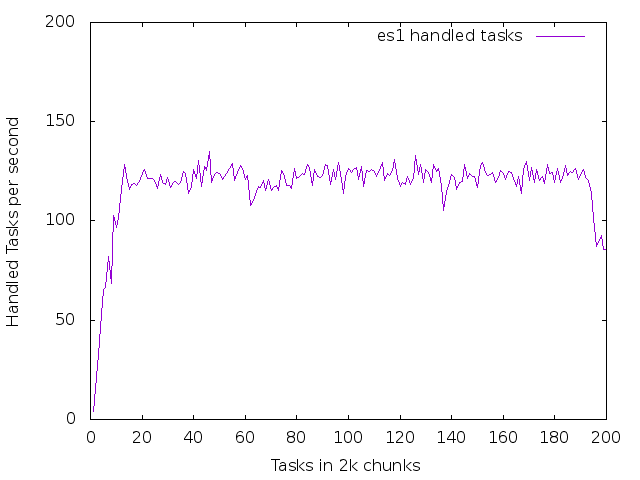
I also captured the handled tasks per second for an unstressed and stressed node as well as the queue adjustment for each node, which you can check out also check out below
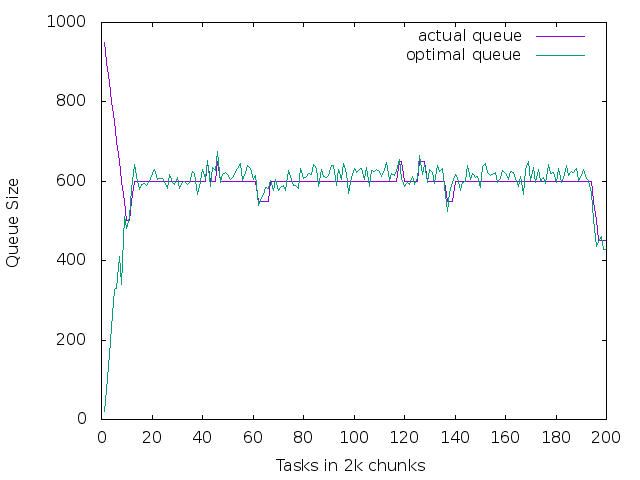
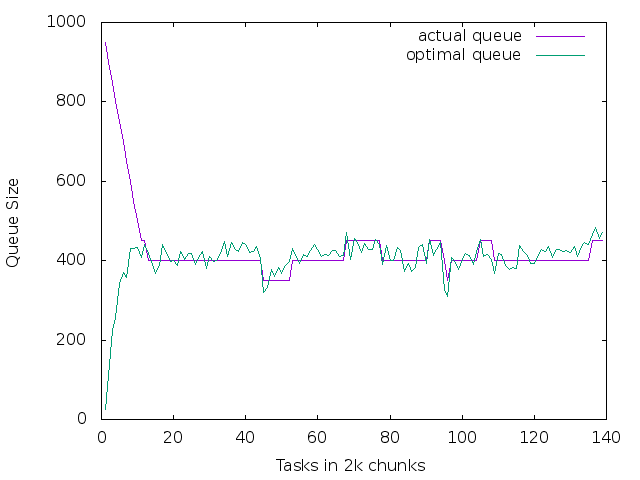
And you can also see the actual versus "optimal" queue in the graphs below.
2 Settings
Here are the settings for the data nodes
thread_pool.search.min_queue_size: 10 thread_pool.search.max_queue_size: 1000 thread_pool.search.initial_queue_size: 1000 thread_pool.search.target_response_rate: 5s thread_pool.search.frame_window: 2000 thread_pool.search.adjustment_amount: 50
3 Nodes
| id | name |
|---|---|
| QLQGW0SqS8KMccjB6sO9FA | perf-client |
| CfDsJaJzTFCc3jDIdT2eJQ | es1 |
| L-_sgGrbR7qiWk8omCcpfw | es2 |
| WrCL-l2mRVSeweXnqFXtQg | es3 |
| hLTtcICaQJGPg82nXBkI-w | es4 |
| buHWM5d5TPuIvjs2URnb-g | es5 |
4 JMeter results
4.1 Results for a stressed cluster with queue auto-adjustment
Each JMeter thread ran a total of 40002 queries.
| JMeter instance | total time | q/s | Avg (ms) | Min | Max | Error |
|---|---|---|---|---|---|---|
| 1 | 1:02:19 | 10.7 | 7266 | 7 | 170708 | 0 |
| 2 | 1:02:18 | 10.7 | 7272 | 7 | 175008 | 0 |
| 3 | 1:02:11 | 10.7 | 7286 | 7 | 211052 | 0 |
| 4 | 0:59:36 | 11.2 | 6982 | 7 | 113438 | 0 |
| 5 | 1:00:15 | 11.1 | 7100 | 7 | 137912 | 0 |
| Average: | - | 10.88 | 7181.2 | 7 | 161623.6 | 0 |
The max was a little high for the previous run, I think partially because stress was killing the
disk so much in this case. Therefore, I did another run to see if the max would come down.
Results from run #2 of a stressed cluster with auto-adjustment, this time I adjusted the
target_response_time to be 4 seconds instead of the 5 seconds I was using above.
| JMeter instance | total time | q/s | Avg (ms) | Min | Max | Error |
|---|---|---|---|---|---|---|
| 1 | 0:55:16 | 12.1 | 6489 | 6 | 15644 | 0 |
| 2 | 0:55:17 | 12.1 | 6501 | 7 | 16212 | 0 |
| 3 | 0:55:14 | 12.1 | 6491 | 7 | 16713 | 0 |
| 4 | 0:55:14 | 12.1 | 6492 | 7 | 17048 | 0 |
| 5 | 0:55:14 | 12.1 | 6500 | 7 | 17381 | 0 |
| Average: | - | 12.1 | 6494.6 | 6.8 | 16599.6 | 0 |
4.2 Results for a stressed cluster without queue auto-adjustment
Each JMeter thread ran a total of 40002 queries.
| JMeter instance | total time | q/s | Avg (ms) | Min | Max | Error |
|---|---|---|---|---|---|---|
| 1 | 1:10:22 | 9.5 | 8268 | 7 | 20297 | 0 |
| 2 | 1:10:21 | 9.5 | 8291 | 7 | 19698 | 0 |
| 3 | 1:10:16 | 9.5 | 8252 | 7 | 21310 | 0 |
| 4 | 1:10:17 | 9.5 | 8257 | 7 | 20514 | 0 |
| 5 | 1:10:15 | 9.5 | 8221 | 7 | 20616 | 0 |
| Average: | - | 9.5 | 8257.8 | 7 | 20487 | 0 |
And after a second run
| JMeter instance | total time | q/s | Avg (ms) | Min | Max | Error |
|---|---|---|---|---|---|---|
| 1 | 1:13:57 | 9.0 | 8667 | 7 | 20297 | 0 |
| 2 | 1:13:57 | 9.0 | 8701 | 7 | 19698 | 0 |
| 3 | 1:13:59 | 9.0 | 8673 | 7 | 21310 | 0 |
| 4 | 1:13:59 | 9.0 | 8657 | 7 | 20514 | 0 |
| 5 | 1:13:58 | 9.0 | 8621 | 7 | 20616 | 0 |
| Average: | - | 9.5 | 8257.8 | 7 | 20487 | 0 |
4.3 Summary
Here's a summary of the JMeter results
| Index | Test Run | Average response time (ms) |
|---|---|---|
| 1 | None #1 | 8257.8 |
| 2 | None #2 | 8257.8 |
| 3 | Auto #1 | 7181.2 |
| 4 | Auto #2 | 6494.6 |
set size ratio 0.75 set style line 1 lc rgb "red" set style line 2 lc rgb "blue" set boxwidth 0.5 set style fill solid set xlabel "Automatic Queue Adjustment" set ylabel "Average response time (ms)" plot [][0:10000] data every ::0::1 using 1:3:xtic(2) title "JMeter response times (no adjustment)" with boxes ls 1, \ data every ::2::3 using 1:3:xtic(2) title "JMeter response times (adjustment)" with boxes ls 2
5 Requests handled by each node
5.1 With queue auto-adjustment
| Node | Handled | Rejected | % Rejected |
|---|---|---|---|
| es1 | 400134 | 0 | 0. |
| es2 | 400114 | 0 | 0. |
| es3 | 501767 | 0 | 0. |
| es4 | 400119 | 0 | 0. |
| es5 | 278491 | 70797 | 25.421647 |
| esclient | 200143 | 0 | 0. |
5.2 Without queue auto-adjustment
| Node | Handled | Rejected | % Rejected |
|---|---|---|---|
| es1 | 399811 | 0 | 0. |
| es2 | 399825 | 0 | 0. |
| es3 | 399800 | 0 | 0. |
| es4 | 399811 | 0 | 0. |
| es5 | 399801 | 0 | 0. |
| esclient | 200000 | 0 | 0. |
6 Per-node threadpool queue size
The tasks are counted in increments of 2000, because that is the frame size for measurements.
6.1 es1 - a healthy node
| Offset | Time for 2k query executions (s) | Avg task time (ms) | Handled tasks/s | Optimal Queue | New Capacity |
|---|---|---|---|---|---|
| 1 | 492 | 175.6ms | 4.02 | 20 | 950 |
| 2 | 126 | 113.1ms | 15.38 | 76 | 900 |
| 3 | 60 | 175.2ms | 32.96 | 164 | 850 |
| 4 | 43 | 115.1ms | 46.47 | 232 | 800 |
| 5 | 30.4 | 424.3ms | 65.65 | 328 | 750 |
| 6 | 30.1 | 276.7ms | 66.33 | 331 | 700 |
| 7 | 24.3 | 199.4ms | 82.23 | 411 | 650 |
| 8 | 29.2 | 160.4ms | 68.34 | 341 | 600 |
| 9 | 19.4 | 248ms | 102.57 | 512 | 550 |
| 10 | 20.7 | 153.2ms | 96.52 | 482 | 500 |
| 11 | 19.6 | 150.7ms | 101.80 | 509 | 500 |
| 12 | 17.2 | 162.9ms | 115.89 | 579 | 550 |
| 13 | 15.5 | 171.9ms | 128.68 | 643 | 600 |
| 14 | 16.3 | 178.8ms | 122.28 | 611 | 600 |
| 15 | 17.2 | 165.9ms | 115.89 | 579 | 600 |
| 16 | 16.8 | 161ms | 118.57 | 592 | 600 |
| 17 | 16.8 | 168.4ms | 118.86 | 594 | 600 |
| 18 | 16.9 | 167.3ms | 118.08 | 590 | 600 |
| 19 | 16.6 | 169.3ms | 120.02 | 600 | 600 |
| 20 | 16.1 | 158.7ms | 124.13 | 620 | 600 |
| 21 | 15.8 | 173.1ms | 125.83 | 629 | 600 |
| 22 | 16.5 | 200.5ms | 121.16 | 605 | 600 |
| 23 | 16.4 | 166.8ms | 121.38 | 606 | 600 |
| 24 | 16.4 | 168.4ms | 121.45 | 607 | 600 |
| 25 | 16.7 | 173.7ms | 119.30 | 596 | 600 |
| 26 | 17.2 | 162.8ms | 116.25 | 581 | 600 |
| 27 | 16.2 | 168.3ms | 123.43 | 617 | 600 |
| 28 | 16.7 | 174.4ms | 119.38 | 596 | 600 |
| 29 | 16.8 | 176.5ms | 118.39 | 591 | 600 |
| 30 | 16.4 | 198.8ms | 121.89 | 609 | 600 |
| 31 | 17.1 | 172.4ms | 116.72 | 583 | 600 |
| 32 | 16.7 | 168.3ms | 119.20 | 596 | 600 |
| 33 | 16.6 | 150.9ms | 119.83 | 599 | 600 |
| 34 | 16.8 | 204.4ms | 118.42 | 592 | 600 |
| 35 | 16.7 | 153.7ms | 119.42 | 597 | 600 |
| 36 | 16 | 166ms | 124.99 | 624 | 600 |
| 37 | 16.1 | 188.5ms | 123.95 | 619 | 600 |
| 38 | 17.5 | 155.1ms | 113.64 | 568 | 600 |
| 39 | 17 | 156.2ms | 117.49 | 587 | 600 |
| 40 | 15.8 | 200.1ms | 126.04 | 630 | 600 |
| 41 | 16.4 | 182.5ms | 121.27 | 606 | 600 |
| 42 | 15.3 | 209.7ms | 130.44 | 652 | 650 |
| 43 | 17 | 156.6ms | 117.22 | 586 | 600 |
| 44 | 15.7 | 183.4ms | 127.33 | 636 | 600 |
| 45 | 15.9 | 185ms | 125.27 | 626 | 600 |
| 46 | 14.8 | 168.2ms | 135.13 | 675 | 650 |
| 47 | 16.7 | 186ms | 119.56 | 597 | 600 |
| 48 | 16.1 | 169.1ms | 123.60 | 618 | 600 |
| 49 | 16.1 | 174.5ms | 124.22 | 621 | 600 |
| 50 | 16.1 | 175.6ms | 123.69 | 618 | 600 |
| 51 | 16.5 | 185.1ms | 121.13 | 605 | 600 |
| 52 | 16.3 | 165.9ms | 122.17 | 610 | 600 |
| 53 | 16 | 189.3ms | 124.56 | 622 | 600 |
| 54 | 15.8 | 197.1ms | 126.52 | 632 | 600 |
| 55 | 15.4 | 179.9ms | 129.19 | 645 | 600 |
| 56 | 16.6 | 171.5ms | 120.21 | 601 | 600 |
| 57 | 16 | 161.8ms | 124.39 | 621 | 600 |
| 58 | 15.6 | 160.4ms | 127.91 | 639 | 600 |
| 59 | 15.8 | 195.1ms | 126.50 | 632 | 600 |
| 60 | 16.5 | 163.6ms | 120.88 | 604 | 600 |
| 61 | 16.2 | 196.1ms | 122.87 | 614 | 600 |
| 62 | 18.5 | 174.6ms | 107.74 | 538 | 550 |
| 63 | 18.1 | 179.7ms | 110.30 | 551 | 550 |
| 64 | 17.6 | 176.3ms | 113.30 | 566 | 550 |
| 65 | 17 | 178.7ms | 117.19 | 585 | 550 |
| 66 | 17.1 | 154.9ms | 116.74 | 583 | 550 |
| 67 | 16.6 | 163.3ms | 120.43 | 602 | 600 |
| 68 | 17.3 | 158.2ms | 115.52 | 577 | 600 |
| 69 | 16.5 | 166.2ms | 120.82 | 604 | 600 |
| 70 | 17.3 | 152.7ms | 115.42 | 577 | 600 |
| 71 | 17 | 174.1ms | 116.97 | 584 | 600 |
| 72 | 16.9 | 163.7ms | 118.06 | 590 | 600 |
| 73 | 17.3 | 166.2ms | 115.44 | 577 | 600 |
| 74 | 15.9 | 185.4ms | 125.44 | 627 | 600 |
| 75 | 16.3 | 154.2ms | 122.26 | 611 | 600 |
| 76 | 16.9 | 153.1ms | 117.83 | 589 | 600 |
| 77 | 16.9 | 187ms | 117.83 | 589 | 600 |
| 78 | 17.2 | 173.7ms | 116.22 | 581 | 600 |
| 79 | 15.8 | 176.7ms | 126.35 | 631 | 600 |
| 80 | 16.4 | 193.7ms | 121.43 | 607 | 600 |
| 81 | 16.3 | 191.5ms | 122.31 | 611 | 600 |
| 82 | 16.1 | 232.4ms | 124.16 | 620 | 600 |
| 83 | 16.2 | 173.6ms | 123.29 | 616 | 600 |
| 84 | 15.5 | 175.8ms | 128.46 | 642 | 600 |
| 85 | 15.8 | 194ms | 126.34 | 631 | 600 |
| 86 | 16.9 | 177.7ms | 117.72 | 588 | 600 |
| 87 | 15.8 | 168.7ms | 125.98 | 629 | 600 |
| 88 | 16.3 | 171.3ms | 122.35 | 611 | 600 |
| 89 | 16.3 | 162.7ms | 122.11 | 610 | 600 |
| 90 | 16.2 | 154ms | 122.99 | 614 | 600 |
| 91 | 15.5 | 155.8ms | 128.35 | 641 | 600 |
| 92 | 15.5 | 213ms | 128.21 | 641 | 600 |
| 93 | 16.9 | 189.6ms | 118.14 | 590 | 600 |
| 94 | 15.8 | 159.2ms | 126.07 | 630 | 600 |
| 95 | 16.5 | 178.9ms | 121.13 | 605 | 600 |
| 96 | 15.4 | 168.9ms | 129.24 | 646 | 600 |
| 97 | 16.1 | 174.8ms | 124.06 | 620 | 600 |
| 98 | 17.5 | 167.8ms | 113.85 | 569 | 600 |
| 99 | 16.3 | 214.6ms | 122.17 | 610 | 600 |
| 100 | 15.8 | 200.8ms | 126.58 | 632 | 600 |
| 101 | 16 | 171.9ms | 124.54 | 622 | 600 |
| 102 | 15.8 | 167.5ms | 126.17 | 630 | 600 |
| 103 | 15.7 | 170.4ms | 126.77 | 633 | 600 |
| 104 | 16.5 | 163.6ms | 121.08 | 605 | 600 |
| 105 | 15.7 | 173.4ms | 127.38 | 636 | 600 |
| 106 | 17 | 154.4ms | 117.22 | 586 | 600 |
| 107 | 15.9 | 160.5ms | 125.23 | 626 | 600 |
| 108 | 16 | 171.2ms | 124.82 | 624 | 600 |
| 109 | 15.8 | 162.1ms | 126.19 | 630 | 600 |
| 110 | 16 | 164ms | 124.88 | 624 | 600 |
| 111 | 16.3 | 169.7ms | 122.52 | 612 | 600 |
| 112 | 15.9 | 156.7ms | 125.51 | 627 | 600 |
| 113 | 15.4 | 160.2ms | 129.43 | 647 | 600 |
| 114 | 16.6 | 160.7ms | 120.39 | 601 | 600 |
| 115 | 16.1 | 193.2ms | 124.06 | 620 | 600 |
| 116 | 16.2 | 172.6ms | 123.14 | 615 | 600 |
| 117 | 15.9 | 181.6ms | 125.68 | 628 | 600 |
| 118 | 15.2 | 177.2ms | 131.11 | 655 | 650 |
| 119 | 16.4 | 186.4ms | 121.24 | 606 | 650 |
| 120 | 17 | 161.9ms | 117.62 | 588 | 600 |
| 121 | 16.7 | 156.1ms | 119.44 | 597 | 600 |
| 122 | 16.8 | 168.9ms | 118.61 | 593 | 600 |
| 123 | 16.3 | 154.9ms | 122.64 | 613 | 600 |
| 124 | 16.8 | 159.5ms | 118.47 | 592 | 600 |
| 125 | 16.4 | 174.9ms | 121.54 | 607 | 600 |
| 126 | 15 | 187.3ms | 132.94 | 664 | 650 |
| 127 | 16.2 | 178.4ms | 123.35 | 616 | 650 |
| 128 | 15.5 | 158.9ms | 128.65 | 643 | 650 |
| 129 | 16.7 | 172.6ms | 119.26 | 596 | 600 |
| 130 | 15.8 | 166.7ms | 125.94 | 629 | 600 |
| 131 | 16 | 174ms | 124.41 | 622 | 600 |
| 132 | 16.7 | 157.5ms | 119.15 | 595 | 600 |
| 133 | 15.5 | 198.4ms | 128.25 | 641 | 600 |
| 134 | 16 | 165.3ms | 124.81 | 624 | 600 |
| 135 | 15.8 | 169.7ms | 126.24 | 631 | 600 |
| 136 | 17 | 169.8ms | 117.28 | 586 | 600 |
| 137 | 19 | 157.5ms | 105.04 | 525 | 550 |
| 138 | 17.4 | 170.1ms | 114.75 | 573 | 550 |
| 139 | 16.7 | 176.4ms | 119.27 | 596 | 550 |
| 140 | 16.1 | 187ms | 123.54 | 617 | 600 |
| 141 | 16.3 | 181.1ms | 122.08 | 610 | 600 |
| 142 | 17.2 | 156.6ms | 115.69 | 578 | 600 |
| 143 | 16.7 | 173.6ms | 119.46 | 597 | 600 |
| 144 | 16.6 | 181.3ms | 119.89 | 599 | 600 |
| 145 | 15.5 | 169ms | 128.38 | 641 | 600 |
| 146 | 16.5 | 202.9ms | 121.16 | 605 | 600 |
| 147 | 16.1 | 202.5ms | 123.88 | 619 | 600 |
| 148 | 16.3 | 169.8ms | 122.17 | 610 | 600 |
| 149 | 16.3 | 179.2ms | 122.63 | 613 | 600 |
| 150 | 17 | 176.2ms | 117.05 | 585 | 600 |
| 151 | 15.6 | 174.3ms | 127.80 | 638 | 600 |
| 152 | 15.4 | 174.3ms | 129.22 | 646 | 600 |
| 153 | 16 | 173.3ms | 124.26 | 621 | 600 |
| 154 | 16.2 | 183.3ms | 123.01 | 615 | 600 |
| 155 | 16.2 | 182.3ms | 123.21 | 616 | 600 |
| 156 | 16 | 163.7ms | 124.24 | 621 | 600 |
| 157 | 16.7 | 197.7ms | 119.23 | 596 | 600 |
| 158 | 16.4 | 174ms | 121.76 | 608 | 600 |
| 159 | 15.9 | 186.2ms | 125.30 | 626 | 600 |
| 160 | 16.1 | 171ms | 123.81 | 619 | 600 |
| 161 | 16.5 | 225.2ms | 121.14 | 605 | 600 |
| 162 | 15.9 | 184.7ms | 125.02 | 625 | 600 |
| 163 | 16 | 194.5ms | 124.61 | 623 | 600 |
| 164 | 16.4 | 148.7ms | 121.64 | 608 | 600 |
| 165 | 17 | 156.1ms | 117.60 | 588 | 600 |
| 166 | 16.3 | 184.5ms | 122.58 | 612 | 600 |
| 167 | 17.5 | 162.9ms | 113.77 | 568 | 600 |
| 168 | 15.8 | 162.4ms | 126.00 | 630 | 600 |
| 169 | 15.3 | 189.3ms | 129.91 | 649 | 600 |
| 170 | 16.5 | 174.3ms | 120.60 | 602 | 600 |
| 171 | 15.7 | 162.7ms | 127.09 | 635 | 600 |
| 172 | 16.7 | 190.1ms | 119.60 | 598 | 600 |
| 173 | 15.8 | 171.6ms | 125.82 | 629 | 600 |
| 174 | 16.6 | 175.6ms | 120.19 | 600 | 600 |
| 175 | 16.3 | 176.8ms | 122.20 | 610 | 600 |
| 176 | 16.7 | 173.5ms | 119.13 | 595 | 600 |
| 177 | 15.5 | 163.2ms | 128.55 | 642 | 600 |
| 178 | 16.1 | 164.4ms | 123.87 | 619 | 600 |
| 179 | 16 | 171.3ms | 124.59 | 622 | 600 |
| 180 | 16.7 | 159ms | 119.22 | 596 | 600 |
| 181 | 15.8 | 158.8ms | 126.47 | 632 | 600 |
| 182 | 16.7 | 154.6ms | 119.56 | 597 | 600 |
| 183 | 16.4 | 197.9ms | 121.54 | 607 | 600 |
| 184 | 15.6 | 168.5ms | 128.11 | 640 | 600 |
| 185 | 16.2 | 187.2ms | 123.07 | 615 | 600 |
| 186 | 15.9 | 179.3ms | 125.10 | 625 | 600 |
| 187 | 16 | 162.7ms | 124.64 | 623 | 600 |
| 188 | 15.8 | 187.3ms | 126.29 | 631 | 600 |
| 189 | 16.5 | 185.8ms | 120.74 | 603 | 600 |
| 190 | 16.2 | 164.4ms | 122.93 | 614 | 600 |
| 191 | 15.8 | 174.4ms | 125.86 | 629 | 600 |
| 192 | 16.4 | 181.2ms | 121.71 | 608 | 600 |
| 193 | 16.6 | 157.4ms | 120.35 | 601 | 600 |
| 194 | 17.5 | 163ms | 113.99 | 569 | 600 |
| 195 | 19.7 | 160ms | 101.02 | 505 | 550 |
| 196 | 22.9 | 142.4ms | 87.33 | 436 | 500 |
| 197 | 22.4 | 133ms | 89.20 | 445 | 450 |
| 198 | 21.6 | 134.5ms | 92.56 | 462 | 450 |
| 199 | 23.3 | 144.8ms | 85.73 | 428 | 450 |
| 200 | 23.3 | 135ms | 85.51 | 427 | 450 |
set xlabel "Tasks in 2k chunks" set ylabel "Queue Size" plot [][0:1000] data using 1:6 title "actual queue" with lines, data using 1:5 title "optimal queue" with lines
This is a graph of handled tasks per second
set xlabel "Tasks in 2k chunks" set ylabel "Handled Tasks per second" plot [][0:200] data using 1:4 with lines title "es1 handled tasks"
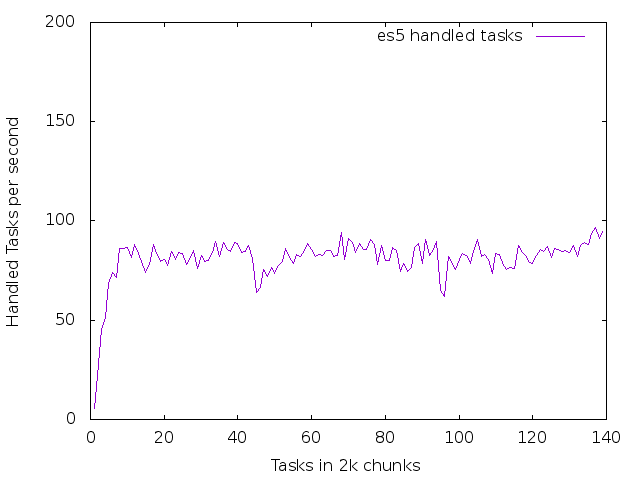
6.2 es5 - an unhealthy node
This node was stressed with stress -i 8 -c 8 -m 8 -d 8 (8 each of IO, CPU, Memory, and HDD workers)
| Offset | Time for 2k query executions (s) | Avg task time (ms) | Handled tasks/s | Optimal Queue | New Capacity |
| 1 | 372 | 72000 | 5.32 | 26 | 950 |
| 2 | 84 | 29600 | 22.24 | 111 | 900 |
| 3 | 44.3 | 16800 | 45.11 | 225 | 850 |
| 4 | 38.7 | 12500 | 51.59 | 257 | 800 |
| 5 | 29.1 | 10100 | 68.69 | 343 | 750 |
| 6 | 26.9 | 8500 | 74.27 | 371 | 700 |
| 7 | 27.9 | 9100 | 71.44 | 357 | 650 |
| 8 | 23.2 | 7700 | 86.05 | 430 | 600 |
| 9 | 23.2 | 7300 | 86.02 | 430 | 550 |
| 10 | 23.1 | 6700 | 86.45 | 432 | 500 |
| 11 | 24.5 | 7200 | 81.44 | 407 | 450 |
| 12 | 22.6 | 5700 | 88.24 | 441 | 450 |
| 13 | 23.9 | 5800 | 83.43 | 417 | 400 |
| 14 | 25.6 | 6300 | 78.04 | 390 | 400 |
| 15 | 27 | 6200 | 73.81 | 369 | 400 |
| 16 | 25.6 | 5800 | 77.93 | 389 | 400 |
| 17 | 22.7 | 5000 | 88.10 | 440 | 400 |
| 18 | 23.9 | 5300 | 83.45 | 417 | 400 |
| 19 | 25 | 5500 | 79.76 | 398 | 400 |
| 20 | 24.8 | 5500 | 80.40 | 401 | 400 |
| 21 | 25.7 | 5700 | 77.56 | 387 | 400 |
| 22 | 23.6 | 5300 | 84.59 | 422 | 400 |
| 23 | 24.7 | 5500 | 80.83 | 404 | 400 |
| 24 | 23.8 | 5200 | 83.89 | 419 | 400 |
| 25 | 23.9 | 5300 | 83.58 | 417 | 400 |
| 26 | 25.5 | 5600 | 78.31 | 391 | 400 |
| 27 | 24.5 | 5500 | 81.50 | 407 | 400 |
| 28 | 23.5 | 5200 | 84.95 | 424 | 400 |
| 29 | 26.2 | 5900 | 76.31 | 381 | 400 |
| 30 | 24.2 | 5500 | 82.38 | 411 | 400 |
| 31 | 25.1 | 5500 | 79.56 | 397 | 400 |
| 32 | 24.9 | 5600 | 80.13 | 400 | 400 |
| 33 | 23.8 | 5300 | 83.95 | 419 | 400 |
| 34 | 22.2 | 4900 | 89.82 | 449 | 400 |
| 35 | 24.3 | 5400 | 82.29 | 411 | 400 |
| 36 | 22.4 | 5000 | 89.16 | 445 | 400 |
| 37 | 23.1 | 5200 | 86.35 | 431 | 400 |
| 38 | 23.5 | 5100 | 84.85 | 424 | 400 |
| 39 | 22.4 | 5200 | 89.13 | 445 | 400 |
| 40 | 22.6 | 4900 | 88.48 | 442 | 400 |
| 41 | 23.7 | 5200 | 84.21 | 421 | 400 |
| 42 | 23.6 | 5300 | 84.54 | 422 | 400 |
| 43 | 22.8 | 5100 | 87.57 | 437 | 400 |
| 44 | 24.6 | 5400 | 81.01 | 405 | 400 |
| 45 | 31.2 | 6500 | 64.02 | 320 | 350 |
| 46 | 30 | 6400 | 66.62 | 333 | 350 |
| 47 | 26.4 | 5300 | 75.52 | 377 | 350 |
| 48 | 27.7 | 5300 | 72.11 | 360 | 350 |
| 49 | 26.1 | 5300 | 76.61 | 383 | 350 |
| 50 | 27.1 | 5300 | 73.57 | 367 | 350 |
| 51 | 25.7 | 5200 | 77.66 | 388 | 350 |
| 52 | 25.1 | 5000 | 79.45 | 397 | 350 |
| 53 | 23.2 | 4600 | 86.11 | 430 | 400 |
| 54 | 24.5 | 5100 | 81.43 | 407 | 400 |
| 55 | 25.4 | 5700 | 78.59 | 392 | 400 |
| 56 | 24 | 5300 | 83.19 | 415 | 400 |
| 57 | 24.3 | 5400 | 82.27 | 411 | 400 |
| 58 | 23.5 | 5200 | 85.05 | 425 | 400 |
| 59 | 22.6 | 5100 | 88.44 | 442 | 400 |
| 60 | 23.3 | 5100 | 85.50 | 427 | 400 |
| 61 | 24.3 | 5400 | 82.12 | 410 | 400 |
| 62 | 24 | 5300 | 83.32 | 416 | 400 |
| 63 | 24.1 | 5400 | 82.84 | 414 | 400 |
| 64 | 23.4 | 5300 | 85.35 | 426 | 400 |
| 65 | 23.4 | 5100 | 85.12 | 425 | 400 |
| 66 | 24.2 | 5400 | 82.35 | 411 | 400 |
| 67 | 24.2 | 5400 | 82.45 | 412 | 400 |
| 68 | 21.2 | 4700 | 94.30 | 471 | 450 |
| 69 | 24.8 | 5800 | 80.48 | 402 | 450 |
| 70 | 21.9 | 5500 | 91.09 | 455 | 450 |
| 71 | 22.4 | 5500 | 89.09 | 445 | 450 |
| 72 | 23.8 | 5800 | 84.00 | 420 | 450 |
| 73 | 22.5 | 5700 | 88.69 | 443 | 450 |
| 74 | 23.3 | 5600 | 85.77 | 428 | 450 |
| 75 | 23.3 | 5900 | 85.58 | 427 | 450 |
| 76 | 22 | 5400 | 90.80 | 454 | 450 |
| 77 | 22.6 | 5600 | 88.40 | 441 | 450 |
| 78 | 25.5 | 6100 | 78.33 | 391 | 400 |
| 79 | 22.7 | 5400 | 87.80 | 439 | 400 |
| 80 | 24.9 | 5400 | 80.16 | 400 | 400 |
| 81 | 24.9 | 5600 | 80.10 | 400 | 400 |
| 82 | 23 | 5200 | 86.83 | 434 | 400 |
| 83 | 23.4 | 5200 | 85.37 | 426 | 400 |
| 84 | 26.8 | 5800 | 74.53 | 372 | 400 |
| 85 | 25.3 | 5700 | 78.76 | 393 | 400 |
| 86 | 26.8 | 5900 | 74.60 | 372 | 400 |
| 87 | 26.1 | 5800 | 76.48 | 382 | 400 |
| 88 | 23.1 | 5200 | 86.49 | 432 | 400 |
| 89 | 22.5 | 5000 | 88.57 | 442 | 400 |
| 90 | 25.4 | 5500 | 78.53 | 392 | 400 |
| 91 | 21.9 | 5000 | 90.91 | 454 | 450 |
| 92 | 24.2 | 5700 | 82.53 | 412 | 450 |
| 93 | 23.2 | 5700 | 85.85 | 429 | 450 |
| 94 | 22.3 | 5600 | 89.48 | 447 | 450 |
| 95 | 30.7 | 7300 | 65.04 | 325 | 400 |
| 96 | 32.2 | 7400 | 62.09 | 310 | 350 |
| 97 | 24.3 | 5000 | 81.99 | 409 | 400 |
| 98 | 25.2 | 5400 | 79.06 | 395 | 400 |
| 99 | 26.5 | 5900 | 75.47 | 377 | 400 |
| 100 | 24.8 | 5600 | 80.44 | 402 | 400 |
| 101 | 23.9 | 5300 | 83.65 | 418 | 400 |
| 102 | 24.2 | 5400 | 82.62 | 413 | 400 |
| 103 | 25.5 | 5600 | 78.40 | 391 | 400 |
| 104 | 23.5 | 5200 | 84.83 | 424 | 400 |
| 105 | 22 | 5000 | 90.68 | 453 | 450 |
| 106 | 24.3 | 5800 | 82.16 | 410 | 450 |
| 107 | 24 | 5700 | 83.33 | 416 | 450 |
| 108 | 24.7 | 6200 | 80.80 | 403 | 450 |
| 109 | 27.1 | 6500 | 73.53 | 367 | 400 |
| 110 | 23.9 | 5700 | 83.64 | 418 | 400 |
| 111 | 24 | 5300 | 83.06 | 415 | 400 |
| 112 | 25.8 | 5600 | 77.50 | 387 | 400 |
| 113 | 26.3 | 5900 | 75.78 | 378 | 400 |
| 114 | 26.1 | 5700 | 76.48 | 382 | 400 |
| 115 | 26.2 | 6000 | 76.14 | 380 | 400 |
| 116 | 22.7 | 5100 | 87.78 | 438 | 400 |
| 117 | 23.5 | 5100 | 84.75 | 423 | 400 |
| 118 | 24.2 | 5500 | 82.42 | 412 | 400 |
| 119 | 25.3 | 5400 | 78.85 | 394 | 400 |
| 120 | 25.4 | 5800 | 78.59 | 392 | 400 |
| 121 | 24.2 | 5400 | 82.38 | 411 | 400 |
| 122 | 23.3 | 5200 | 85.80 | 429 | 400 |
| 123 | 23.5 | 5200 | 84.86 | 424 | 400 |
| 124 | 22.9 | 5200 | 87.29 | 436 | 400 |
| 125 | 24.5 | 5400 | 81.60 | 408 | 400 |
| 126 | 23.2 | 5200 | 85.93 | 429 | 400 |
| 127 | 23.3 | 5100 | 85.61 | 428 | 400 |
| 128 | 23.6 | 5200 | 84.73 | 423 | 400 |
| 129 | 23.5 | 5100 | 85.06 | 425 | 400 |
| 130 | 23.7 | 5300 | 84.27 | 421 | 400 |
| 131 | 22.8 | 5100 | 87.56 | 437 | 400 |
| 132 | 24.3 | 5300 | 82.22 | 411 | 400 |
| 133 | 22.8 | 5200 | 87.43 | 437 | 400 |
| 134 | 22.4 | 4900 | 89.07 | 445 | 400 |
| 135 | 22.6 | 4900 | 88.15 | 440 | 400 |
| 136 | 21.3 | 4200 | 93.46 | 467 | 450 |
| 137 | 20.6 | 3400 | 96.68 | 483 | 450 |
| 138 | 21.9 | 2700 | 91.17 | 455 | 450 |
| 139 | 21.1 | 1200 | 94.47 | 472 | 450 |
set xlabel "Tasks in 2k chunks" set ylabel "Queue Size" plot [][0:1000] data using 1:6 title "actual queue" with lines, data using 1:5 title "optimal queue" with lines
This is a graph of handled tasks per second
set xlabel "Tasks in 2k chunks" set ylabel "Handled Tasks per second" plot [][0:200] data using 1:4 with lines title "es5 handled tasks"
7 What happens if the target_response_rate is set too low?
For simplicity, let's assume queries arrive at a rate of 1 per second, and take 5 seconds to
execute, the target_response_rate is set to 2s on our node. We assume 1 thread to handle
queries. We go with a small frame window (5) so that every 5 executed tasks we calculate the optimal
queue size. We also start with a queue size of 25 and adjust by 15 every time it's adjusted (to
illustrate what happens the best).
| Incoming Task Num | Queued tasks | Current executing task | Queue Size |
|---|---|---|---|
| 0 | 0 | 0 | 25 |
| 1 | 0 | 1 | 25 |
| 2 | 1 | 1 | 25 |
| 3 | 2 | 1 | 25 |
| 4 | 3 | 1 | 25 |
| 5 | 4 | 1 | 25 |
| 6 | 4 | 2 | 25 |
| 7 | 5 | 2 | 25 |
| 8 | 6 | 2 | 25 |
| 9 | 7 | 2 | 25 |
| 10 | 8 | 2 | 25 |
| 11 | 8 | 3 | 25 |
| 12 | 9 | 3 | 25 |
| 13 | 10 | 3 | 25 |
| 14 | 11 | 3 | 25 |
| 15 | 12 | 3 | 25 |
| 16 | 12 | 4 | 25 |
| 17 | 13 | 4 | 25 |
| 18 | 14 | 4 | 25 |
| 19 | 15 | 4 | 25 |
| 20 | 16 | 4 | 25 |
| 21 | 16 | 5 | 25 |
| 22 | 17 | 5 | 25 |
| 23 | 18 | 5 | 25 |
| 24 | 19 | 5 | 25 |
| 25 | 20 | 5 | 25 |
| 26 | 20 | 6 | 10 |
| 27 | 20 | 6 | 10 |
| 28 | 20 | 6 | 10 |
| 29 | 20 | 6 | 10 |
| 30 | 20 | 6 | 10 |
| 31 | 19 | 7 | 10 |
| 32 | 19 | 7 | 10 |
| 33 | 19 | 7 | 10 |
| 34 | 19 | 7 | 10 |
| 35 | 19 | 7 | 10 |
| 36 | 18 | 8 | 10 |
set xlabel "Task Count" set ylabel "Tasks" plot [][0:30] data using 1:2 with lines title "tasks queued", \ data using 1:3 with lines title "tasks handled", \ data using 1:4 with lines title "queue limit"
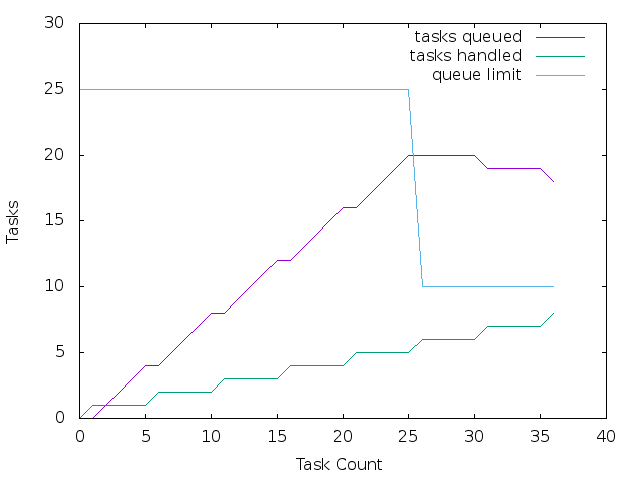
At task # 26 (where the first measurement/adjustment happens), 26 seconds have elapsed, 5 total
tasks have executed, and the queue is at 20. ES would then calculate the optimal queue size, L =
λW with λ as being able to handle 0.2q/s and with the target response rate of 2 seconds as W,
this gives us a queue size of 0.2 * 2 = 0.4, or essentially 0, this is our node currently can't
keep up with the rate.
With our auto queuing adjustment and no min or max, the queue would trend towards 0 and eventually only a single request at a time would be handled.